
ChatGPT & Co – Basiswissen Künstliche Intelligenz (KI)
Generative KI-Systeme wie ChatGPT, DALLE und Midjourney revolutionieren gerade unsere Welt und eröffnen auch bei der Automatisierung dokumentenbasierter Prozesse neue Horizonte. Von KI spricht man schon lange und sie wird bereits einige Zeit genutzt. Aber was hat das Thema nun so in den Vordergrund gespült? Wir wollen hier einen Überblick geben und wichtige Begriffe und Basiswissen erklären.
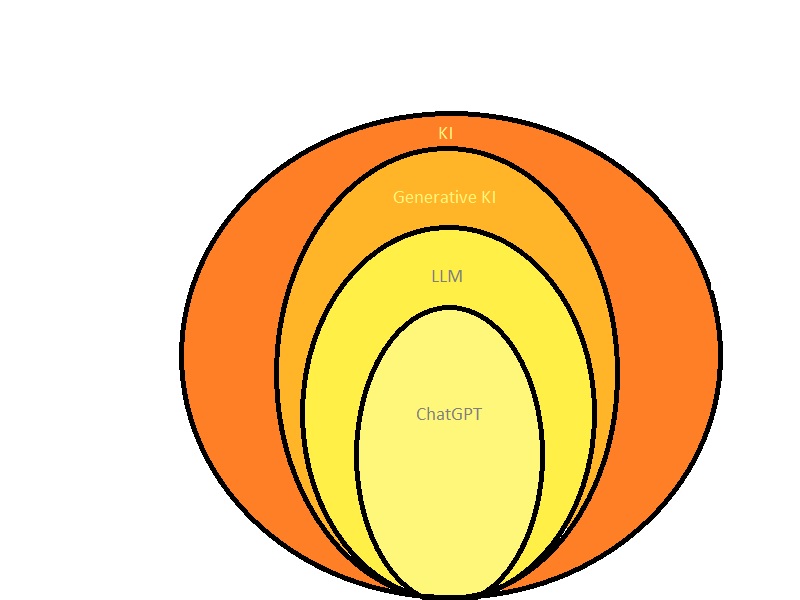
Erscheinungsformen von Künstlicher Intelligenz (Bild: A. Stadler)
Erscheinungsformen von Künstlicher Intelligenz (Bild: A. Stadler)
ChatGPT läutet neue Ära im KI-Bereich ein
Inhalt dieses Artikels
Ohne Zweifel hat vor allem ChatGPT generative KI der breiten Masse nahegebracht. Der Chatbot wurde im November 2022 veröffentlicht und hat sich seither rasend schnell verbreitet. Doch Künstliche Intelligenz begegnete der Allgemeinheit auch schon davor, beispielsweise in Form von Sprachassistenten wie Siri oder Alexa. Jedoch können Large Language Modelle, zu denen ChatGPT wie auch die deutsche Entwicklung Aleph Alpha und Dolly 2.0 zählen, weitaus mehr. Sie sind nicht nur in der Lage menschliche Sprache und Texteingaben zu verstehen, sondern auch Zusammenhänge zu erkennen und eigene Texte und Antworten zu generieren. Zudem können sie für eine Vielzahl von anderen Zwecken wie Übersetzungen, Zusammenfassungen, Präsentationen und Programmieraufgaben eingesetzt werden.
So funktionieren Large Language Modelle
Ein Large Language Modell ist ein künstliches neuronales Netz, das maschinelles Lernen mit großen Datensätzen praktiziert. Während des Trainings lernt das Modell, Wörter, Sätze und Absätze zu analysieren und daraus abgeleitete Informationen zu verstehen. Es erlernt auch Grammatikregeln, semantische Beziehungen und Kontextabhängigkeiten. Aufgrund vieler Trainingsdaten ist das neuronale Netz in der Lage, das nächste Wort in einem Satz zu prognostizieren. Dies geschieht nach dem Motto, dass beispielsweise »Regenbogen« folgt, wenn der Satz mit »Bei Regen und Sonnenschein, sieht man einen« beginnt.
Das Training eines Large Language Models erfordert eine enorme Rechenleistung und große Mengen an Daten. Modelle wie GPT-3 (GPT steht für Generative Pre-Trained Transformer), auf dem ChatGPT basiert, bestehen aus Milliarden von Neuronen und werden auf leistungsstarken Computerclustern trainiert.
Generative und diskriminative KI
Da ChatGPT neue Inhalte wie Texte, Präsentationen und Programm-Codes generieren kann, handelt es sich um ein generatives KI-System. Die Ergebnisse generativer KI-Systeme sind nicht deterministisch, also nicht immer gleich. Dies bedeutet, dass man bei gleicher Eingabe verschiedene Ergebnisse erhalten kann. Fragt man beispielsweise nach einem Backrezept für einen Marmorkuchen, kann man verschiedene Varianten erhalten, ebenso bei der Interpretation eines Gedichtes oder bei der mehrfachen Eingabe der gleichen Thematik.
Im Gegensatz zu generativen KI-Modellen gibt es die diskriminativen KI-Modelle, die keinen Content erzeugen, sondern vielmehr darauf spezialisiert sind, bestehende Datensätze auszuwerten und eindeutige Fakten zu extrahieren. Daten lassen sich so schneller klassifizieren als Menschen hierzu in der Lage wären. Beispielsweise können Dokumente nach Dokumentarten wie Rechnungen und Angebote unterteilt und einzelne Positionen wie Rechnungssumme und Rechnungsdatum herausgelesen werden. Es lassen sich nach bestimmten Entscheidungsgrenzen aber auch Krankheitsbilder von Patienten einordnen.
Allerdings gibt es auch Überschneidungen von und Kombinationen aus generativer und diskriminativer KI, wenn man beispielsweise Fakten extrahieren und anschließend personalisieren möchte. So kann man etwa aus einem Produkthandbuch bestimmte Punkte abfragen und extrahieren, die dann im Kontext der Frage als Antwort personalisiert als komprimierter Text zur Verfügung gestellt werden.
KI ermöglicht verschiedene Automatisierungsstufen
KI lässt sich generell in verschiedenen Level zur Automatisierung anwenden, was sich an der Bearbeitung von E-Mails aus E-Mail-Postfächern zeigen lässt. Auf dem untersten Level 1 werden, wie in den meisten E-Mail-Programmen üblich, Spam-E-Mails von regulären E-Mails aussortiert. Bei E-Mails auf Level 2 wird das Thema erkannt – handelt es sich um eine Anfrage, eine Rechnung oder eine Bestellung. Bei Level 3 können konkrete Informationen aus unstrukturierten Daten extrahiert werden – etwa Schadensinformationen bei einem Versicherungsfall. Auf Level 4 lassen sich mit generativer KI bereits personalisierte Antworten vorgenerieren, die dann von einem menschlichen Mitarbeitenden überprüft und bearbeitet werden. Level 5 spiegelt dann den vollautomatisierten Modus wider, in dem direkt eine Antwort generiert und ausgesendet wird.
Prompt Engineering
Ein Prompt ist die Anforderung in der Eingabezeile eines generativen KI-Modells. Unter »Prompt Engineering« versteht man den Prozess des Erstellens effektiver und spezifischer Anweisungen oder »Prompts« für Sprachmodelle wie GPT-3.5. Das Ziel des Prompt Engineering besteht darin, die gewünschten Ergebnisse von Sprachmodellen zu verbessern, indem man die Art und Weise, wie man Anweisungen formuliert, optimiert.
Der Prozess des Prompt Engineering umfasst verschiedene Schritte. Zunächst muss man das gewünschte Ergebnis oder die gewünschte Antwort genau definieren und den Kontext angeben. Dabei kann der Nutzende bestimmte Formatierungen oder Anforderungen an die Antwort angeben. Zusätzlich ist es möglich Content mitzuliefern, den das KI-Modell möglicherweise nicht kennt wie eigenes Domainwissen. Prompt Engineering ist häufig ein iterativer Prozess, da man weitere Anweisungen an erhaltene Antworten geben kann, um zu optimierten Ergebnissen zu kommen. Prompt Engineering ändert ein zugrundeliegendes Modell nicht, jedoch fließt mitgelieferter Kontext in das KI-System ein und steht dann generell zur Verfügung. Daher sollten vertrauliche und private Informationen nicht eingegeben werden.
Finetuning von KI-Modellen
Finetuning beziehungsweise Feinabstimmung kann man durchführen, um ein vortrainiertes KI-Modell auf ein bestimmtes Fachgebiet zu spezialisieren. Im Finetuning-Prozess werden die Gewichte und Parameter des vortrainierten Modells anhand der spezifischen Trainingsdaten angepasst. In der Regel werden nur wenige Schichten des Modells freigegeben, während die früheren Schichten, die bereits ein allgemeines Verständnis der Sprache oder der Muster gelernt haben, beibehalten werden. Dadurch wird verhindert, dass das Modell seine bereits erlernten Fähigkeiten verliert, während es sich auf die neue Aufgabe spezialisiert. Da Entwickler beim Finetuning ein KI-Modell nicht von Grund auf trainieren müssen, spart dies Zeit, Rechenressourcen und Daten. Im Gegensatz zum Prompt Engineering führt Finetuning zu langfristigen Änderungen des KI-Modells.
Weitere Artikel

OpenText investiert in F&E-Zentren in Irland
Mit einem Ausbau der Forschungszentren in Irland erhöht OpenText sein Engagement in europäische Cloud-, Security- und KI-Entwicklungen. Dadurch werden die Entwicklungskapazitäten in Europa insgesamt weiter ausgebaut und stärker fokussiert.
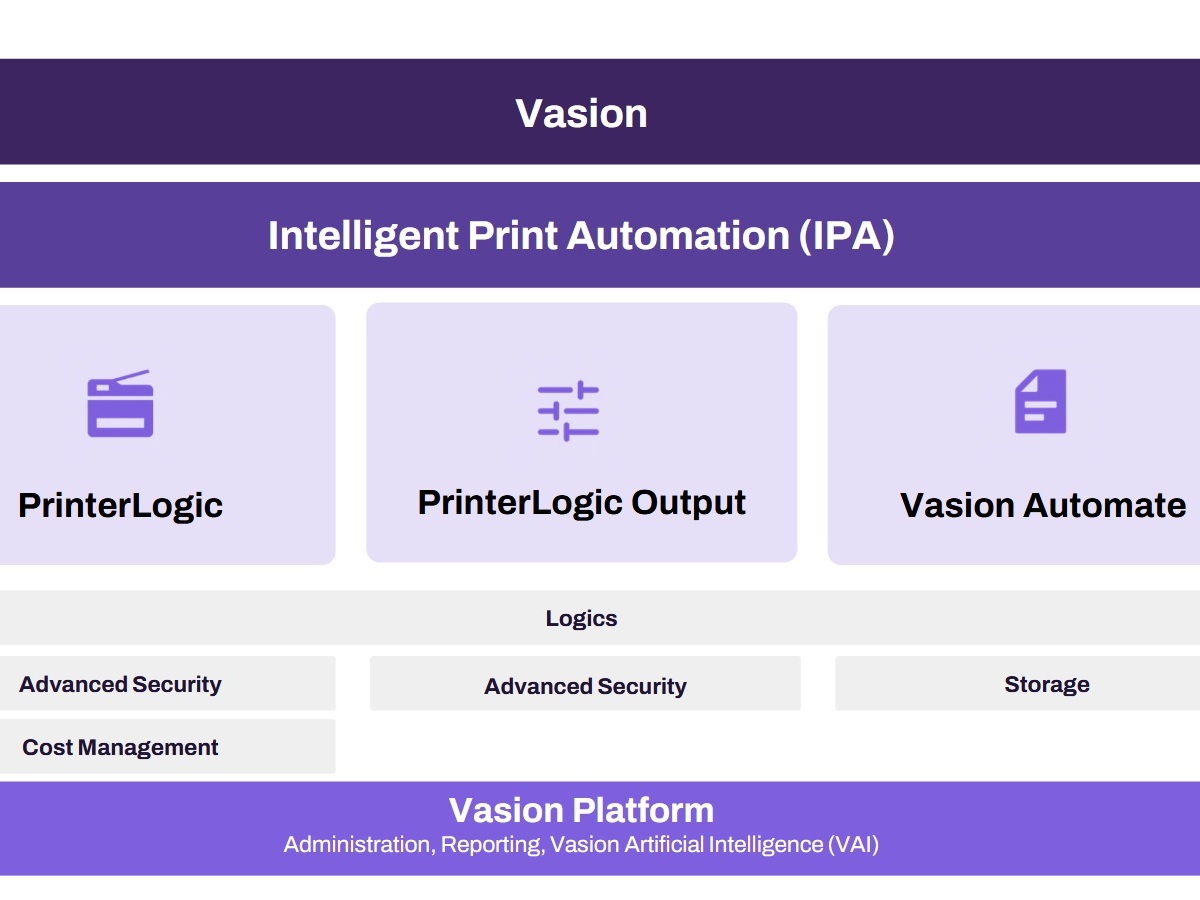
Vasion kann mehr als Print Management
Mit »IPA« erweitert der US-Softwarehersteller Vasion das klassische Druckmanagement um intelligente Automatisierungsfunktionen. Basis ist die cloud-basierte Plattform »Vasion«, die hierzulande bereits von namhaften Unternehmen genutzt wird.